Intro
LangSmith is a powerful platform designed to enhance the development experience with any Language Model (LLM) framework. It allows you to debug, evaluate, and monitor your language model applications and intelligent agents. Whether you are building production-grade LLM applications or experimenting with LLMs, LangSmith has got you covered.
What is LangSmith?
" LangSmith is a platform for building production-grade LLM applications. It lets you debug, test, evaluate, and monitor chains and intelligent agents built on any LLM framework and seamlessly integrates with LangChain, the go-to open source framework for building with LLMs. LangSmith is developed by LangChain, the company behind the open source LangChain framework. "
Essentially, LangSmith functions as an external logging service for your LLM calls. It integrates seamlessly into any application using LangChain, but can also be utilized without it if you choose to do so.
The capabilities are best explained with examples so let's just dive in how to get started:
Setup
First let's install LangChain. LangSmith is directly integrated in LangChain's package.
pnpm add langchainThen add necessary environment variables. You can generate your API key inside your "Smith". link
# your environment variable file
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
# if not specified, defaults to "default"
export LANGCHAIN_PROJECT=<your-project>For SvelteKit we can emit the export statement and simply copy the variables into our .env file like so:
// .env
LANGCHAIN_TRACING_V2='true'
LANGCHAIN_ENDPOINT='https://api.smith.langchain.com'
LANGCHAIN_API_KEY='<your-api-key>'
LANGCHAIN_PROJECT='<your-project>'And... that's it!
The LangSmith team really did a fantastic job! It's on by default
and so easily integratable in your existing applications you don't even have to touch any of your
code if you already have existing endpoints. How awesome is that!
If you don't have any endpoints yet, you can simply create a new one like such:
//endpoint
import { ChatOpenAI } from "langchain/chat_models/openai";
const llm = new ChatOpenAI()
await llm.call("Hello, world!");Need a bit more help? Don't know how to start building your chatbot?
Check out this article on
how to build the simplest fully functional Chatbot ever. LangChain and SvelteKit
make it possible in under 50 lines of code.
Caution: If you are using SvelteKit like me, your environment variables will not be available in development mode by default, which means LangSmith won't pick up your LLM calls while you are running your project locally.
To fix this we have to install dotenv-expand and change our vite.config.ts file like so:
// vite.config.ts
import { loadEnv, defineConfig } from 'vite';
import dotenvExpand from 'dotenv-expand';
import { sveltekit } from '@sveltejs/kit/vite';
export default defineConfig(({ mode }) => {
//FIX FOR ENV VARIABLES IN DEVELOPMENT!
if (mode === 'development') {
const env = loadEnv(mode, process.cwd(), '');
dotenvExpand.expand({ parsed: env });
}
return {
plugins: [sveltekit()]
};
});Let's go up a bit in complexity though. Your endpoint will most likely not look that simple. In my case, for my first test, I am going to use a SvelteKit endpoint that looks like this:
// /api/chat/+server.ts
import type { Config } from '@sveltejs/adapter-vercel';
import { PRIVATE_OPENAI_KEY } from '$env/static/private';
import { json } from '@sveltejs/kit';
import { ChatOpenAI } from 'langchain/chat_models/openai';
import { HumanMessage, AIMessage } from 'langchain/schema';
export const config: Config = {
runtime: 'edge'
};
export const POST = async ({ request }) => {
try {
const requestData = await request.json();
if (!requestData) throw new Error('No request data');
const reqMessages = requestData.messages.map((msg) => ({
role: msg.role,
content: msg.content
}));
if (!reqMessages) throw new Error('no messages provided');
const chatMessages = reqMessages.map((msg) =>
msg.role === 'user' ? new HumanMessage(msg.content)
: new AIMessage(msg.content)
);
const chat = new ChatOpenAI({
temperature: 0.7,
openAIApiKey: PRIVATE_OPENAI_KEY
});
const chatResponse = await chat.call([...chatMessages]);
const chatResponseText = chatResponse.content;
return json({
result: chatResponseText,
error: !chatResponseText }, { status: 200 });
} catch (err) {
console.error(err);
return json(
{
error: true,
errorMsg: 'There was an error processing your request'
},
{ status: 500 }
);
}
};First results
After calling the Endpoint in our Frontend:
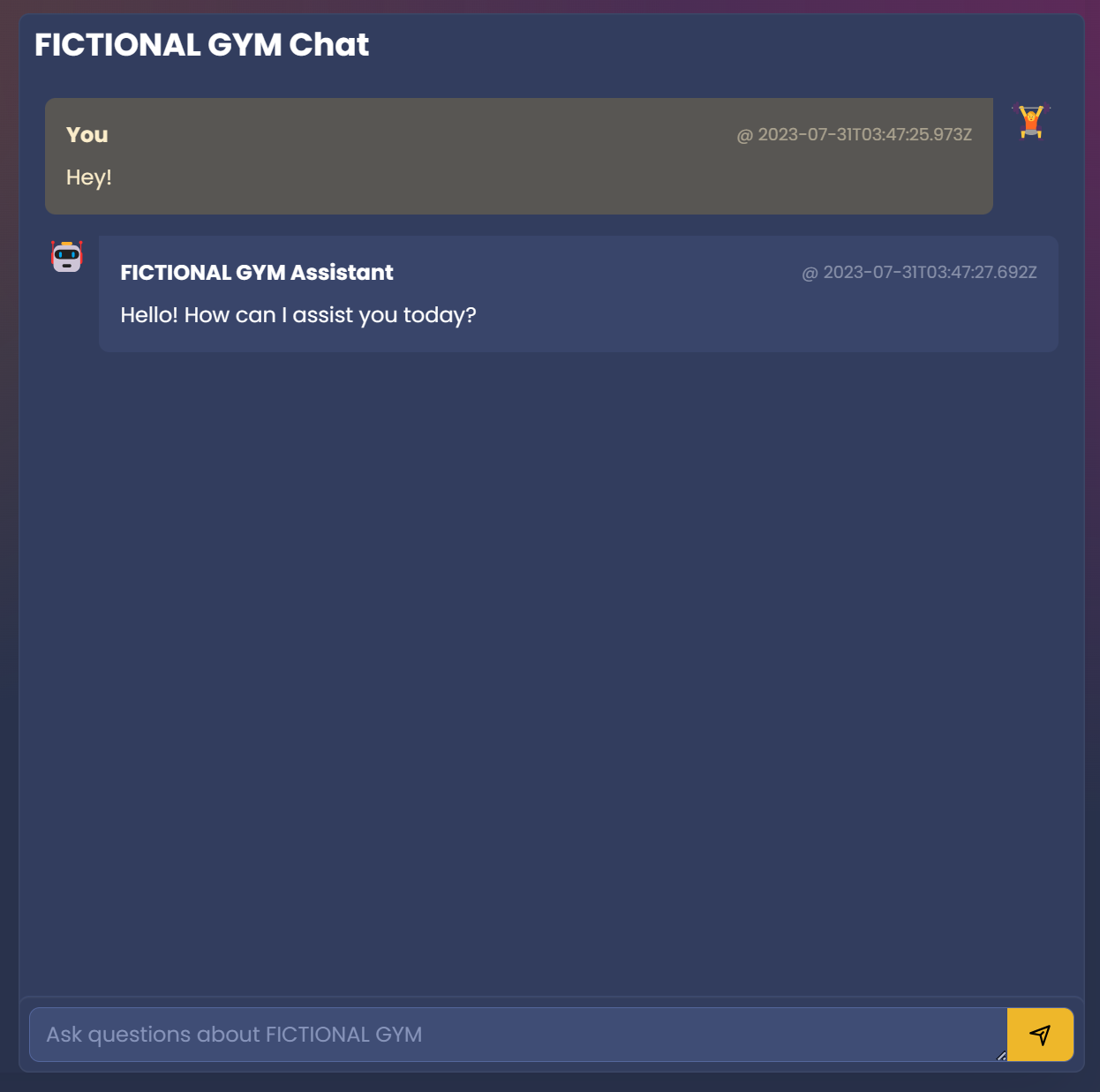
We can check our LangSmith account for the details:
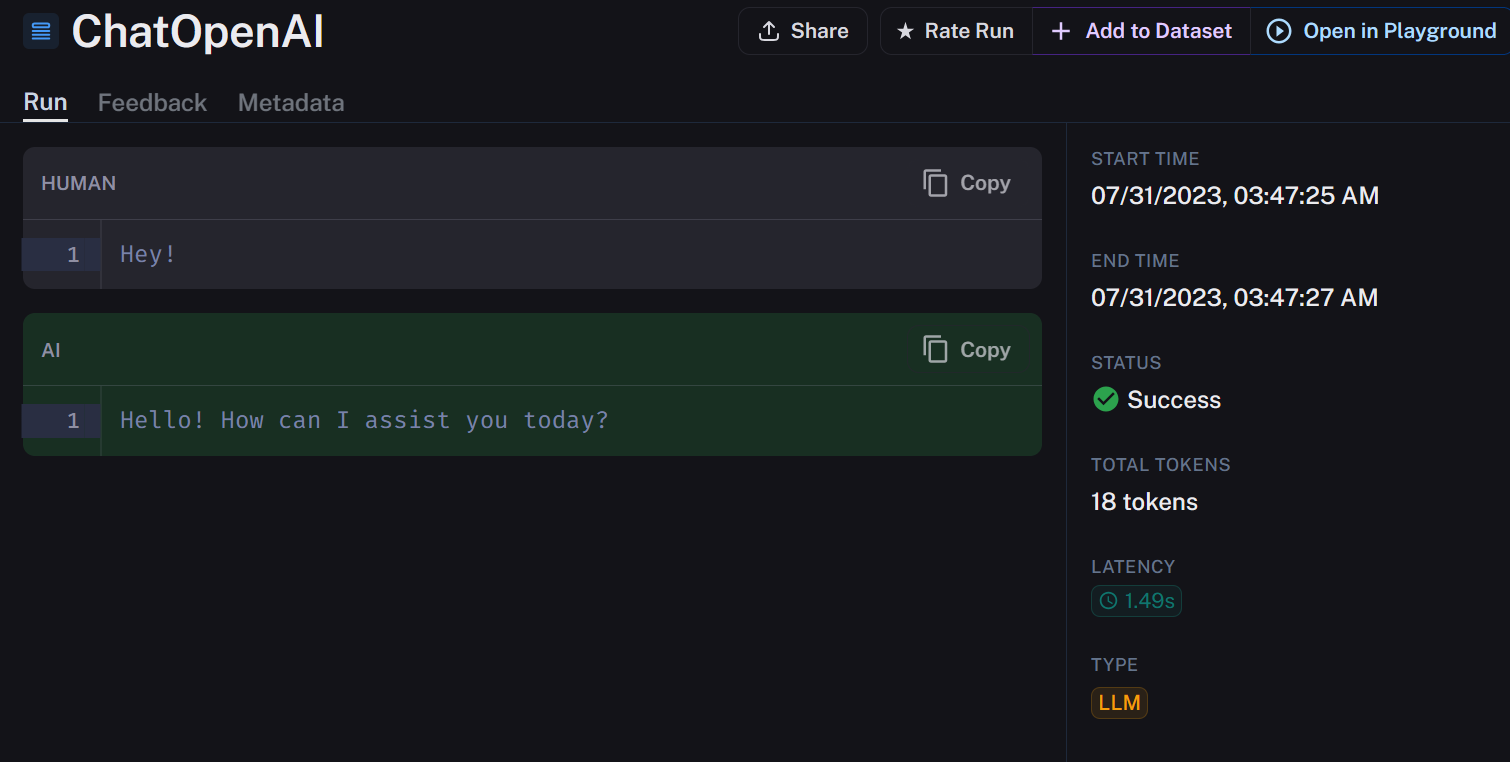
Awesome it works!
We can immediately see some interesting things like if it resulted in Status Success, the total Tokens and Latency. These metrics alone are pure gold and reveal an immediate use case: Evaluating queries and prompts against each other.
I spend a lot of time trying to find the right prompt for every use case and have probably rewritten my system message dozens of times.
How did I know one is better than the other? To be honest, it's just guessing or a lot of manual work. Well, with LangSmith, it is neither of those.
In your Project overview you can immediately see the comparison between LLM calls
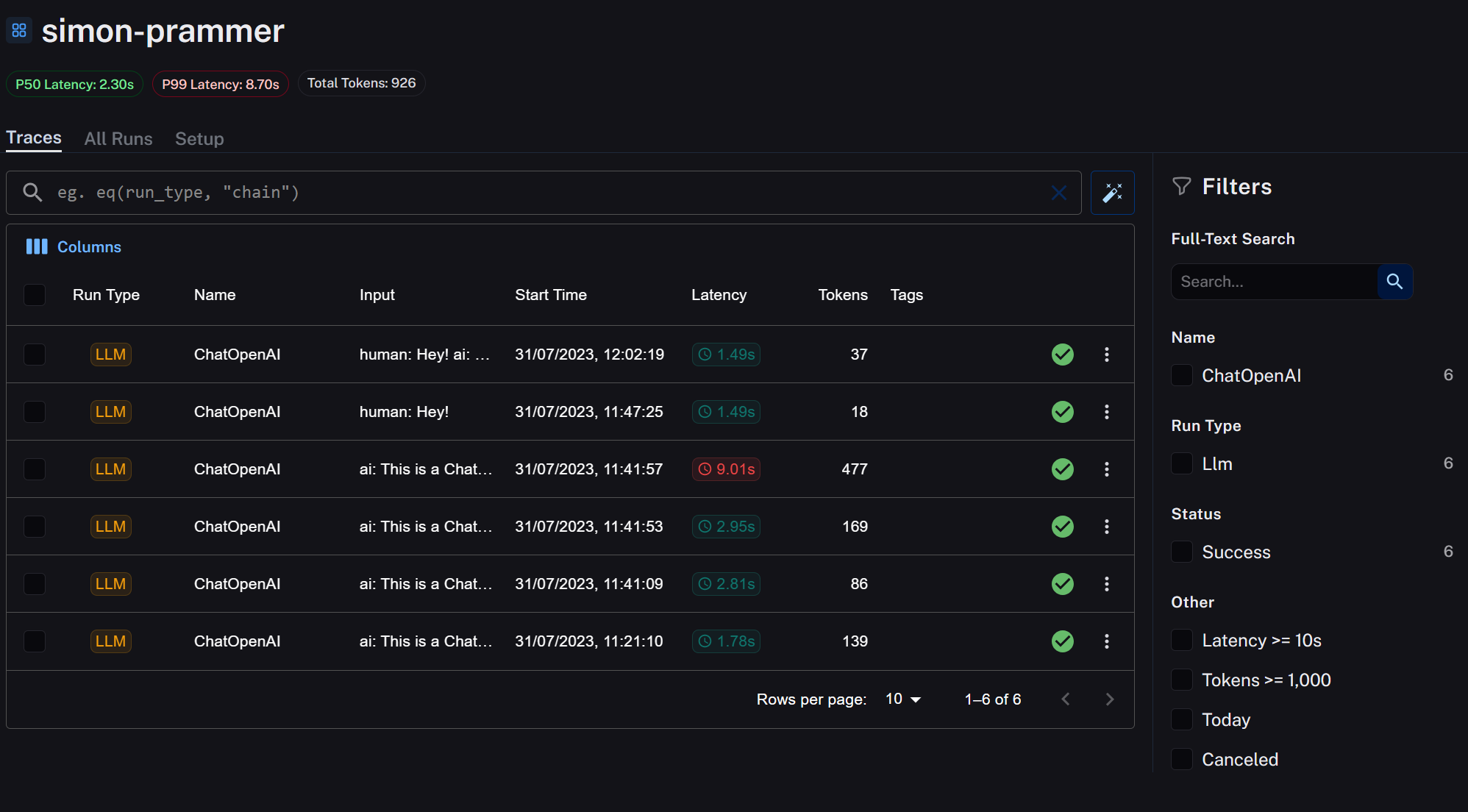
Comparing two Chains
One case I remember vividly is when OpenAI Functions came out. I rewrote a lot of my code to work with Functions only to find out that actually the prompt I had before was the better one in the first place. You know what, let's reconstruct that problem and I'll show you what I mean:
In my Project Personal Trainer AI I have a functionality to generate a Workout based on the Users Profile and prompt.
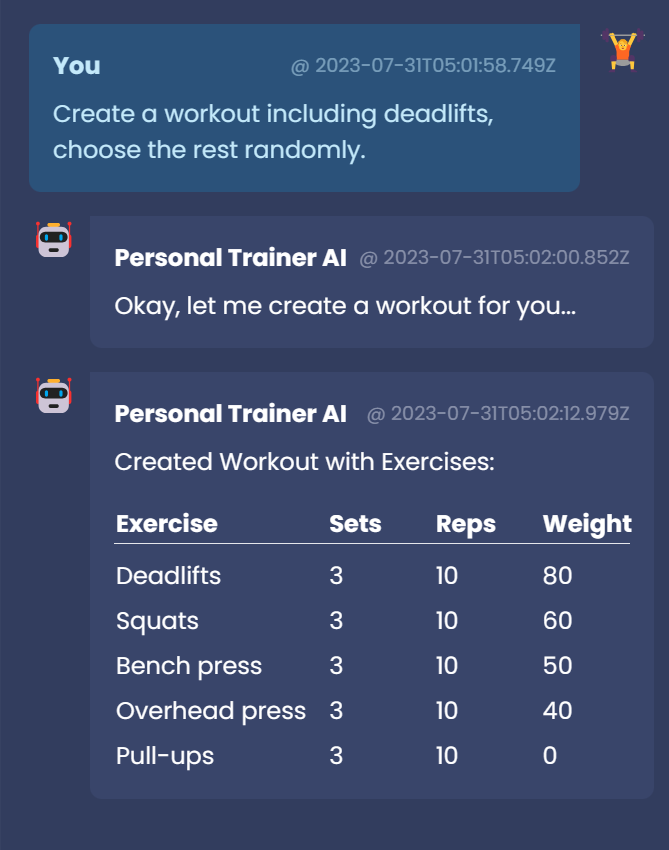
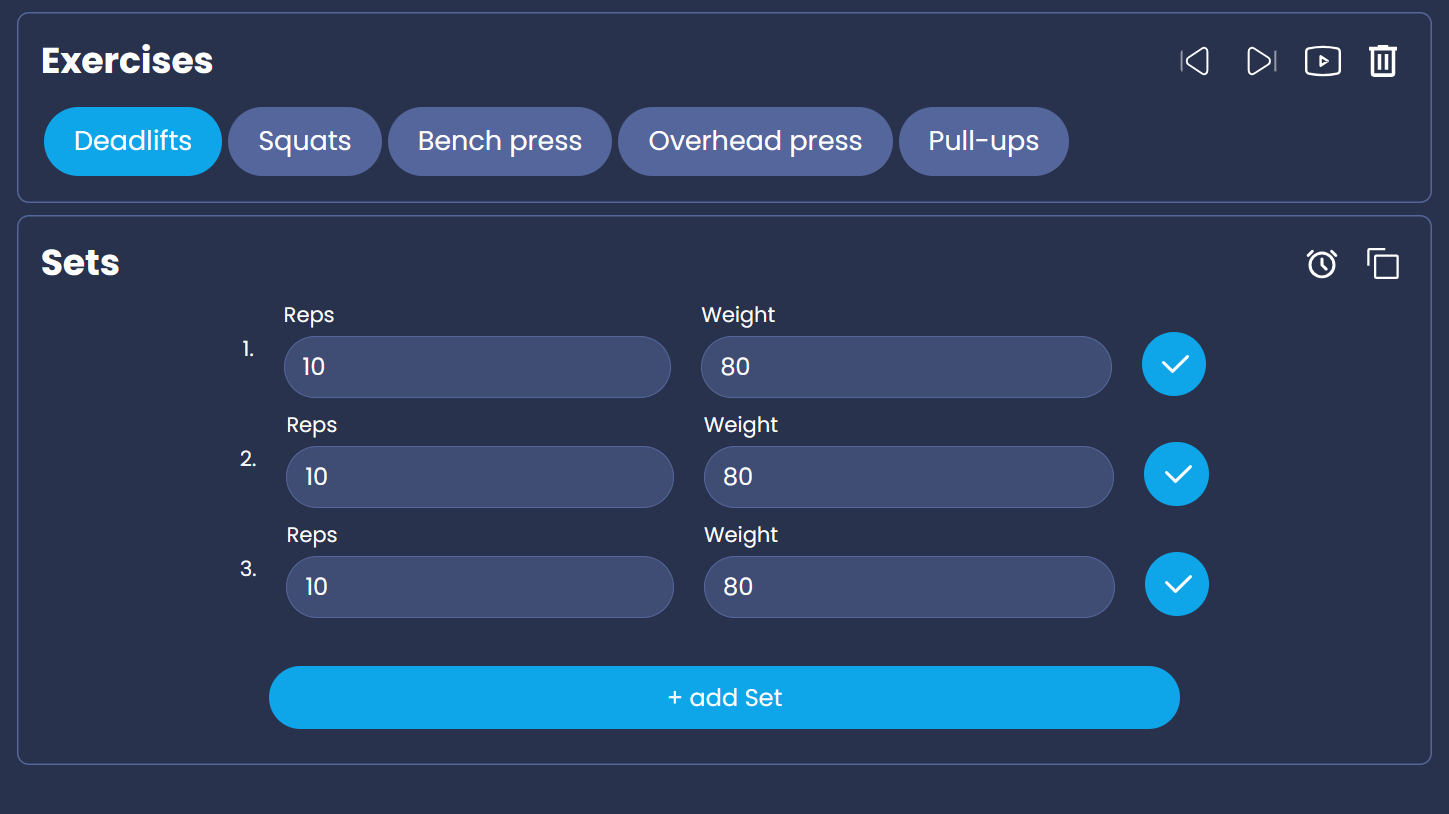
To keep it simple I won't go too much into detail how it works, but in a nutshell I define inputFormat + input and explain to the LLM the outPutformat (+examples).
My first prompt details that I want the result to be a csv with predefined headers. If we check LangSmith the traces looks like this:
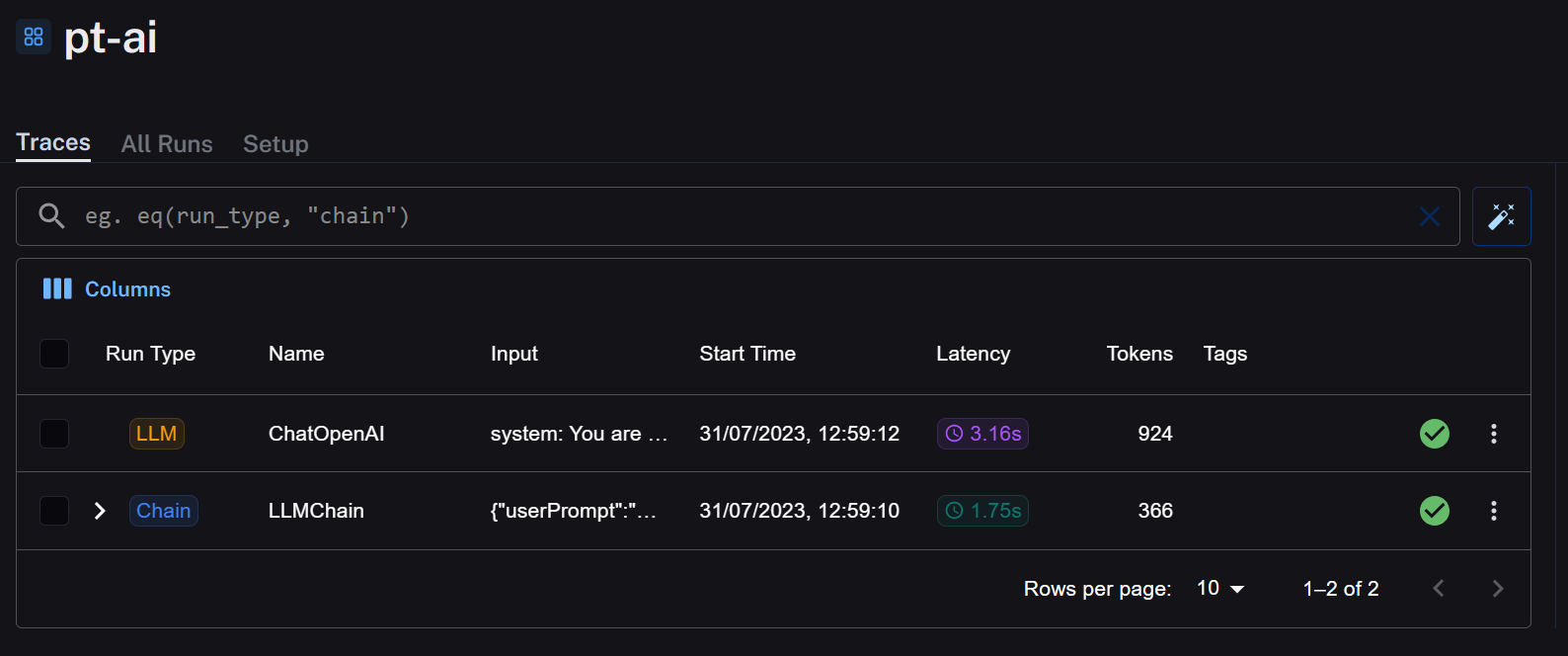
The first result with Run Type "Chain" is a classification process I run to identify the users intent before choosing the correct endpoint for the LLM.
The second trace is the actual LLM call. It took 3.16s and 924 Tokens.
My initial reaction was "Wait...924 Tokens? That's a lot". These metrics alone give me loads of ideas how to improve. I'm okay with 3 seconds execution time but reducing the Token could would be great.
I can do that by shortening my system prompt, sending less examples to the LLM, fine-tuning the prompt etc. So many knobs I could turn, and thanks to LangSmith I learned that I should indeed turn them.
Now let's look at the second way to call the LLM. Using OpenAI Functions to generate the Workout.
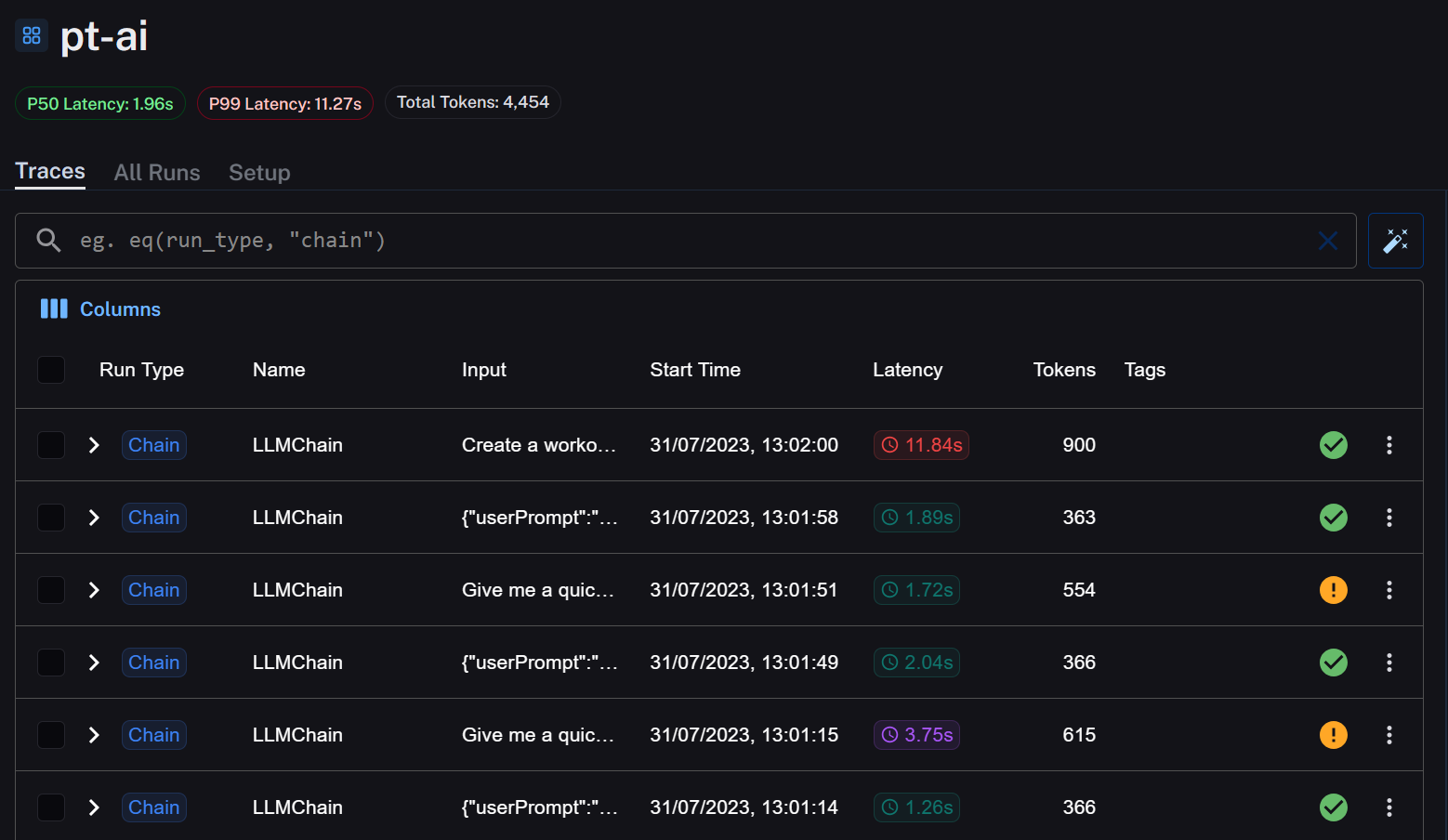
Oof, this does not look good. Not only did it fail 2 times before actually working, it also took 4 Times as long as the other Chain!!
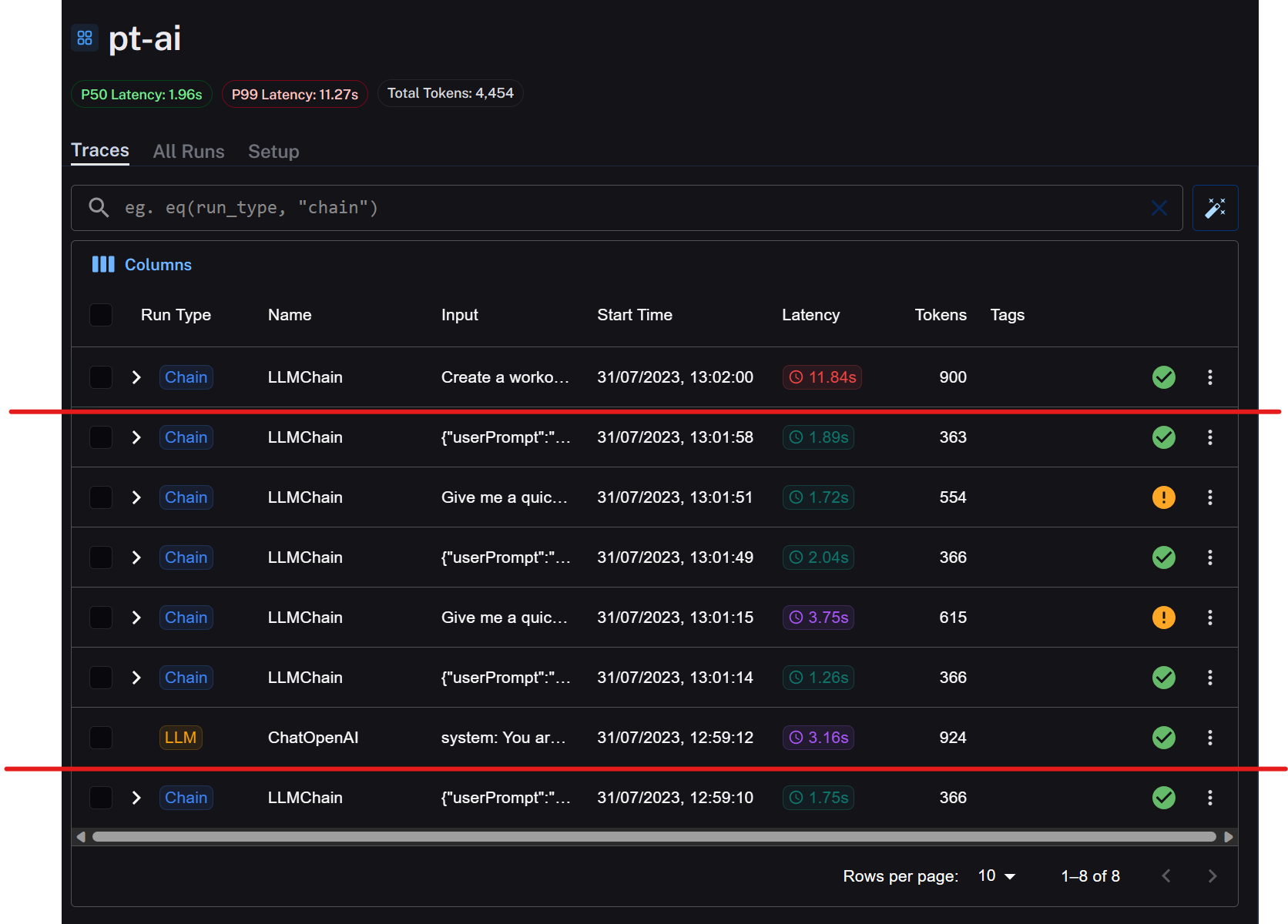
This result confirmed my hunch. Calling the Workout generation with OpenAI Functions is NOT the right call on this particular endpoint.
Having the numbers black on white is a game changer. I can now confidently say that I should go with the first option AND I learned what I could do to improve the performance in general.
Conclusion
We have barely scratched the surface of what LangSmith can do, but this blog post is getting awfully long so I will cover more in the next one.
What I have seen so far is: LangSmith is a game-changer for developers working with language model applications. It provides a comprehensive set of tools and features to debug, evaluate, and monitor LLMs, making the development process more efficient and effective.
The feature I want to explore next are probably data sets. They basically allow you to evaluate your chains by choosing which results are satisfactory, exporting and feed them to your LLM to further improve quality! How cool is that!
To learn more about LangSmith check out the official documentation!
Thank you for reading, and see you in the next one! 👋