Motivation
Since fine-tuning was announced by OpenAI, it has been a very prominent topic in the AI community. Many members have explored different approaches, applied them to their use cases, and shared their results.
Most of those articles and posts are focused on comparing fine-tuned GPT-3.5 with GPT-4.
"But... how about few-shot GPT-3.5 vs fine-tuned GPT-3.5?"
OpenAI's GPT models are exceptionally good at following instructions based on examples, which is known as "few-shot learning".
When it comes to handling more complex chains that require multiple instructions and specific output formats, I have found that few-shot GPT-3.5 Turbo performs incredibly well, while still being affordable and fast.
For that reason, this approach is my go-to, and I am using it for most of my LLM endpoints in production.
That being said, I have not tried fine-tuning yet, and the premise of using fewer tokens, faster response times, and still getting a nicely formatted result seems very promising.
The fundamental question that I want to explore in this article is:
"Can fine-tuned GPT-3.5 turbo outperform few-shot GPT-3.5 Turbo?"
Spoilers: In my case, it did not!
But there are very particular reasons for that, and I am certain you can learn from my mistakes!
What is Fine-tuning?
Let's quickly go over what fine-tuning is so we are all on the same page before diving deeper.
Fine-tuning is a process in machine learning where a pre-trained model, such as GPT-3.5, is further trained on a specific task. This process is often used to adapt a general model to a specific task or to adjust its behavior, making it more suitable for the task at hand.
In the case of language models like GPT-3.5, fine-tuning can help in achieving more consistency in output form and in performing specific tasks more efficiently. However, it's important to note that it is not typically well-suited for teaching new information to the models.
Use cases that the community currently recommends fine-tuning for are:
- Mimicking Tone or Style: To make your model output text in a particular tone or style.
- Outputting Specific Schemas: If you need your model to be more consistent with a specific output format.
- Text Classification and Tagging Tasks: If you seek standardized form for classification or tagging tasks
Let's also establish the potential benefits & drawbacks:
Potential Benefits
- Quality of Responses: Fine-tuned GPT-3.5 has been demonstrated to generate GPT-4 quality responses or even surpass them in some cases.
- Cost and Speed: Fine-tuning GPT-3.5 can reduce model latency and inference costs over GPT4. This not only improves efficiency but also enables further enhancements to the user experience.
Potential Drawbacks
- Use-Case Dependency: The effectiveness of fine-tuning GPT-3.5 in comparison to using GPT-4 is highly dependent on the specific use-case. In many instances, few-shot GPT-4 has outperformed a fine-tuned model while also being more cost-effective.
- Efford and Cost of fine-tuning: Fine-tuning GPT-3.5 requires a significant amount of time and resources. This can be a barrier to entry for many developers and organizations.
If you want to dive deeper, there are already fantastic articles out there covering this topic in more detail. I can especially recommend the articles on the official Langchain blog!
Few-shot vs Fine-tuned
While all these benefits seem great, they mostly compare the to GPT-4. No articles seem to address the elephant in the room:
"How does it stack up against few-shot GPT3.5 Turbo?"
Intrigued by this question, I decided to investigate and test it myself.
I hypothesize that many LLM-centered applications still use few-shot GPT-3.5 Turbo for most of their core chains.
In fact, the arguably most important chain in my personal project "personaltrainer-ai", which creates exercises based on the user's data, is a few-shot GPT-3.5 Turbo chain.
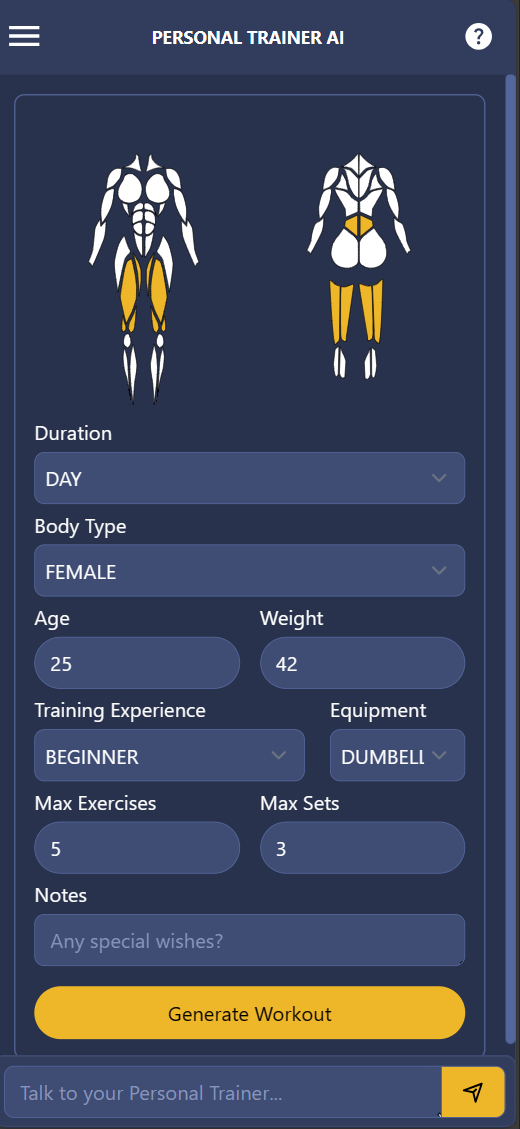
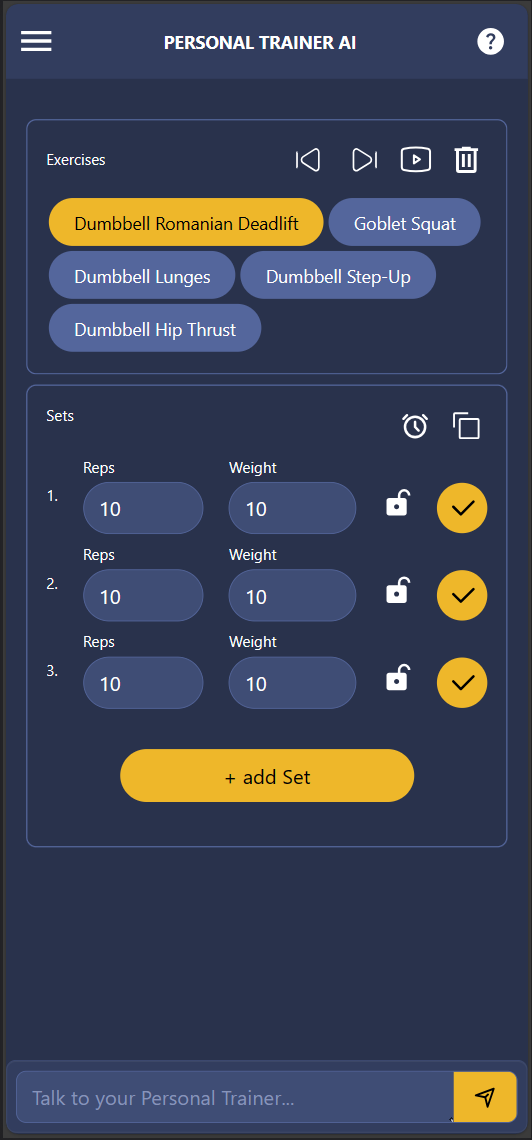
This is not a simple chain. It has a multitude of inputs, transformations, few-shot examples, and parsers to come to its result. It might be challenging to get a fine-tuned model to perform well on this complex of a chain.
But it falls under the use-case category of "Outputting Specific Schemas", so I think it's a valid candidate to try it!
Planning & Preparation
Before we start we need to plan and prepare a bit. To be able to compare the two different approaches accordingly I decided on the following steps:
- 1. Select Evaluation Metrics: Choose metrics to compare on.
- 2. Create Training & Evaluation Set: Training set will be used to fine-tune. The evaluation set will be used to evaluate the fine-tuned models performance.
- 3. Set a Baseline: Determine current model's performance based on our metrics.
- 4. Fine-tune: Complete the process of fine-tuning through OpenAIs API.
- 5. Compare Models: Evaluate the fine-tuned model and compare.
Metrics
For me to consider the fine-tuned model a success it has to perform better than my current model on at least some of these metrics:
- Success%: Rate of success vs failure.
- Latency: How long did the LLM call take.
- Cost: Cost in $ based on tokens model cost per token.
- Score: Rating from 1-100 how fitting the result was to the user.
For the metric "Score" I wrote a custom GPT-4 evaluator to score between 1-100 how well the created exercises fit the user. This will be a measurement to make sure I do not have a loss of quality in responses.
You can find my "model-evaluator" prompt on the LangChain hub here or pull it directly from the hub:
from langchain import hub
obj = hub.pull("simonp/model-evaluator")A simplified psydo-code version of the evaluation process looks something like this:
//get runs from LangSmith client that I tagged for evaluation
const runs: Run[] = await getRunsFromLangSmith({tags});
//loop through runs and evaluate with custom evaluator
for await (const run of runs) {
const evaluationResult = await RunnableSequence.from([
{
//extract and convert the run to "model-evaluator" prompts variables
},
//https://smith.langchain.com/hub/simonp/model-evaluator
ChatPromptTemplate.fromPromptMessages(
modelEvaluatorPrompt
),
new ChatOpenAI({
modelName: 'gpt-4',
}),
new StringOutputParser()
]).invoke(run);
//logging evaluation score to a logfile, the run itself or a dataset
//score will be one of our metrics to evaluate models against each other
await logEvaluationScore(run, evaluationResult);
}Training & Evaluation Sets
Some users of the community reported positive results with only 10-30 examples for fine-tuning. In order to see if this applies to my somewhat more complex use-case I decided to go in the middle and ended up at 23 examples.
Additionally to that I prepared 12 evaluation runs that should be used to test the fine-tuned model to evaluate the performance.
Measuring my baseline
So all in all its 35 runs. Let's measure them on our metrics. Heres how the current few-shot GPT3.5 turbo chain performed:
- Success%: 95.6%
- AvgLatency: 2645ms
- AvgCost: $0.00185
- AvgScore: 91.86 - scored by custom evaluator
Well...this performed much better than expected. The score is relatively high even though I am not passing in specific few-shot examples filtered with a retrieval algorithm. Especially the cost per run will be hard to beat with a fine-tuned model.
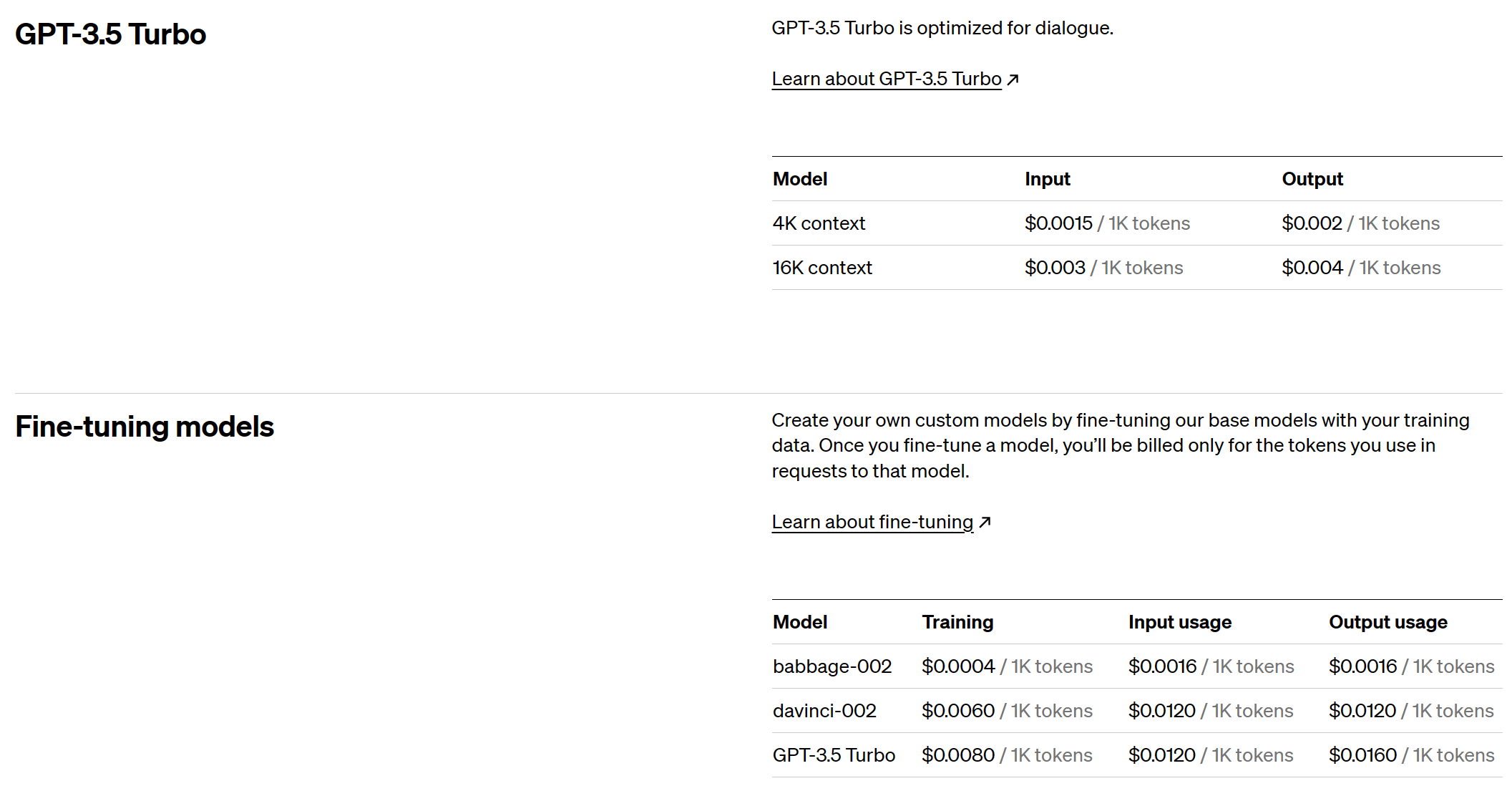
As we can see in the pricing, fine-tuned calls are 8x more expensive! We have to save a lot of token in our prompt to cut even.
Few-shot GPT3.5 turbo will be tough to beat...but if we don't try we won't know for sure.
Fine-Tuning Process
This was actually a lifesaver. I am usually a JavaScript guy, but with the code neatly prepared and ready to use, I decided to jump in, plug in my environment variables, and go through the process.
Because I already prepared my datasets for training and evaluation it only took me a to go through the cookbook.
Then after waiting about 20 minutes the fine-tuning process was complete and I had a Model-Id I could plug into my system.
Running the Fine-tuned Model
I prepared a new endpoint, got rid of examples and formatting instructions in my prompt, and prepared for my first run.
Formatting instructions and examples make up the majority of my tokens. The model is fine-tuned now, so it does not need those anymore to return a valid result...right?
Wrong.
The run failed. Invalid output format.
Okay, admittedly I have a bit of a special case. In order to save as many tokens as possible, I am instructing GPT to use a CSV output format. A perfect result looks something like this:
---name,sets,reps,weight
Hip Thrust,3,12,20
Glute Bridge,3,15,0
Bicep Curl,3,10,8
Hammer Curl,3,12,5
Concentration Curl,3,15,5---I found that if the end result should be an array, instructing the LLM output to be CSV rather than JSON was faster and saved tokens.
This is because CSV does not repeat all keys for every entry. Instead, the keys are listed once in the header, and the rest of the output are the pure values.
Even though all the outputs of examples that I trained the fine-tuned model on were in CSV format, it did not seem to "remember" and instead answered in typical GPT-3 fashion:
Exercise 1: Deadlifts
- Set 1: 8 reps
- Set 2: 8 reps
- Set 3: 6 reps
- Set 4: 6 reps
Exercise 2: Lunges
- Set 1: 10 reps per leg
- Set 2: 10 reps per leg
- Set 3: 8 reps per leg
- Set 4: 8 reps per leg
Exercise 3: Glute Bridges
- Set 1: 12 reps
- Set 2: 12 reps
- Set 3: 10 reps
- Set 4: 10 reps
Exercise 4: Leg Press
- Set 1: 8 reps
- Set 2: 8 reps
- Set 3: 6 reps
- Set 4: 6 reps
Feel free to adjust the weights and repetitions based on your current strength and fitness level. Don't forget to warm up before starting your workout and cool down and stretch afterwards. If you have any specific preferences or additional notes, please let me know!
I was a little bit hesitant to add back the formating instructions because I need to save as many tokens as possible for fine-tuning to be worth it but let's see if that solves the problem:
---
barbell deadlift,4,10-12,rest 60s
lunge,4,10-12,rest 60s
lying leg curl,4,10-12,rest 60s
tricep pushdown,4,10-12,rest 60s
---
The workout includes deadlifts and three other exercises. Each exercise should be performed for 4 sets with a rep range of 10-12. Rest for 60 seconds between sets.Better! But it still fails.
It did not add the CSV header, so it can't properly assign the values to the keys.
If I encounter the problem with a normal chain, I would naturally say, "I just need to give it some examples so it knows how to format the output."
But if I add back the examples, then it completely defeats the purpose of fine-tuning, doesn't it?
Maybe it was a one-time thing. Let's run the evaluation set to see the results over multiple runs.
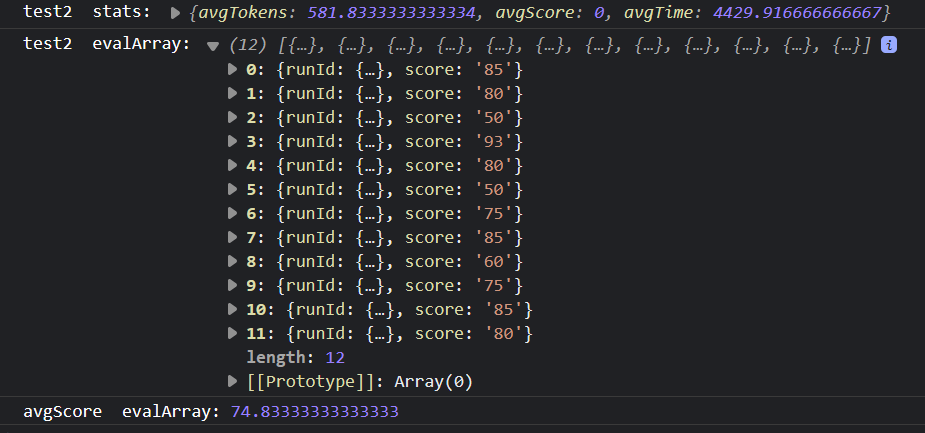
- Success%: 25%. Only 3 chains completed successfully.
- AvgLatency: 4429ms - 1.7x slower
- AvgCost: $0.00814 - 4.4x more
- AvgScore: 74.83 - The model sometimes did not output an exercise name which lowered the score
Oh boy...every single metric except for tokens is worse. Only that tokens per 1k are 8 times the price so it ends up being more expensive anyway.
So... I think I have to admit defeat on this one:
"My fine-tuned GPT-3.5 turbo model failed."
And you know what? This is quite expected!
It took many iterations to get my current few-shot GPT3.5 Turbo chain to the point where it is now! It would be incredibly lucky to get a better result on the first try with fine-tuning.
My key takeaways
What we gained here is extremely valuable insights and data to improve our next iteration! Theres a few things I already have in mind that I would do differently next time:
Use more training examples
Actually, OpenAI recommends 50-100 examples for fine-tuning. We learned that my 23 were not enough to burn in a specific output format. Next time, I will go for at least 75!

Make the output format as simple as possible
If I were to redo the process, I would train the model on a simplified version of the output, then add in the extra formatting with an output parser! This saves tokens as well as makes it easier for the model to stay consistent.
Hip Thrust,3,12,20
Glute Bridge,3,15,0
Bicep Curl,3,10,8
Hammer Curl,3,12,5
Concentration Curl,3,15,5Fine-tune only with "perfect" examples
In my training set, I did have some examples that were not scored "100" by my evaluator. With a little more patience, I can gather enough "perfect" examples to train the next version.
The experience we gained along the way
Gaining valuable insights and learnings, increasing proficiency in using the LangSmith API, gathering valuable runs and datasets, having reusable custom evaluators, etc. These things make all the effort more than worth it.
Few-shot GPT3.5 turbo is awesome!
Honestly, when I saw the initial metrics, I already knew it was going to be near impossible to outperform GPT-3.5 turbo on the first attempt. However, I can't wait to try again with a better prepared dataset and see if I can beat it!
Last but not least...it was fun!
I absolutely love "playing" with AI. This field is still so new, there is a lot to learn and discover. Experimenting and trying new approaches itself is half of the joy.
With that being said, I hope I could give some value to this awesome community by sharing my experience.
Thank you for reading and see you in the next one!👋