Introduction
This Blog post is basically a love letter to the newly introduced Expression Language from Langchain. I hope you will be as blown away as I am by what it does for us developers.
Langchain Expression Language provides a declarative approach to streamline the pipelining of Langchain operations, making it more concise and understandable.
What makes it different from the Langchain we already know and love?
It allow us to easier combine and modify chains, offering a flexible and customizable experience for working with language models. With improved async support and new methods like invoke, batch, and stream, handling single inputs, lists of inputs, and streaming outputs has never been easier.
Why is this important? Well, the Langchain Expression Language aims to provide a flexible and customizable language for working with language models and building complex chains of operations. By simplifying the process and enhancing readability, developers can focus on creating more accurate and efficient language models.
In this blog post we’ll take a look at how Expression Language works, rewrite one of our endpoints to use it and analyse what that changes for us. Let’s get started!
A "Simple" Endpoint
Let's first see an implementation of an endpoint of how we would usually do it. (in Javascript)
//convert to chat messages
const chatMessages = requestData.messages.map((msg: Message) =>
msg.role === 'user' ? new HumanMessage(msg.content)
: new AIMessage(msg.content)
);
//define my model
const chat = new ChatOpenAI({
openAIApiKey: PRIVATE_OPENAI_KEY
});
//call the llm
const chatResponse = await chat.call(
[
new SystemMessage(systemMsg),
...chatMessages
]);
//get response content
const result = chatResponse.content;Well its not bad right? Its a linear process from step to step, which we are mostly used to. But now imagine we add more and more steps to this process: Prompt templates - Example selectors - Retrievers - Moderation - multiple calls - parallel calling of LLMs - parsing the output - retry on failure.
You can imagine how messy this gets!
Using Expression Language
My own approach to solve the mess after a certain complexity, was to write a lot of puzzle piece functions that handle one of those responsibilities and then plug and play them to get the result I wanted.
Well, this is basically what the Langchain Expression Language does, but better! It enables us to encapsulate our entire call in one place and easily swap out parts of it. Let's take a look:
const result = await RunnableSequence.from([
new ChatOpenAI({ openAIApiKey: PRIVATE_OPENAI_KEY }),
new StringOutputParser()
]).invoke([
...requestData.messages.map((msg) =>
msg.role === 'user' ? new HumanMessage(msg.content)
: new AIMessage(msg.content)
)
]);This is it?!
Yep! I can't really describe how beautiful this is to me. It's so clean ❤️
For the sake of explaining what is going on exactly, let's split the code up into chunks though.
//convert messages to the right format
const chatMessages = requestData.messages.map((msg) =>
msg.role === 'user' ? new HumanMessage(msg.content)
: new AIMessage(msg.content)
);
//declare our chain -> it will run through every step from top to bottom
const chain = RunnableSequence.from([
new ChatOpenAI({ openAIApiKey: PRIVATE_OPENAI_KEY }),
new StringOutputParser()
]);
//start the chain with input and await result
const result = await chain.invoke([...chatMessages]);Because we are using OpenAI as our model, we convert the messages to the right format (HumanMessage and AIMessage).
Depending on the model you use, converting the messages might be different or not necessary at all.
A chain is basically a sequence of operations where the output of each step flows as input into the next one.
Invoke with Input -> Chain Step One: Model call -> Chain Step Two: Parser
When we invoke the chain, we give the go sign for the process to kick off and pass in the first input, which could be for example a user's message 'hello'.
'Hello' enters the RunnableSequence where it will be sent to OpenAI. The output from OpenAI will then be passed as input into the StringOutputParser.
StringOutputParser gives us the final result, which will be something like 'Hello! How can I assist you today?'.
How awesome is it, that we can see the whole chain, even if it gets increasingly complex, in one easy to read statement?
You can also add your SystemMessage when you invoke for more control over how the LLM responds.
Another thing that might blow your mind is, that with LangSmith, LangChains logging service, we can see and analyse all the steps seperately!
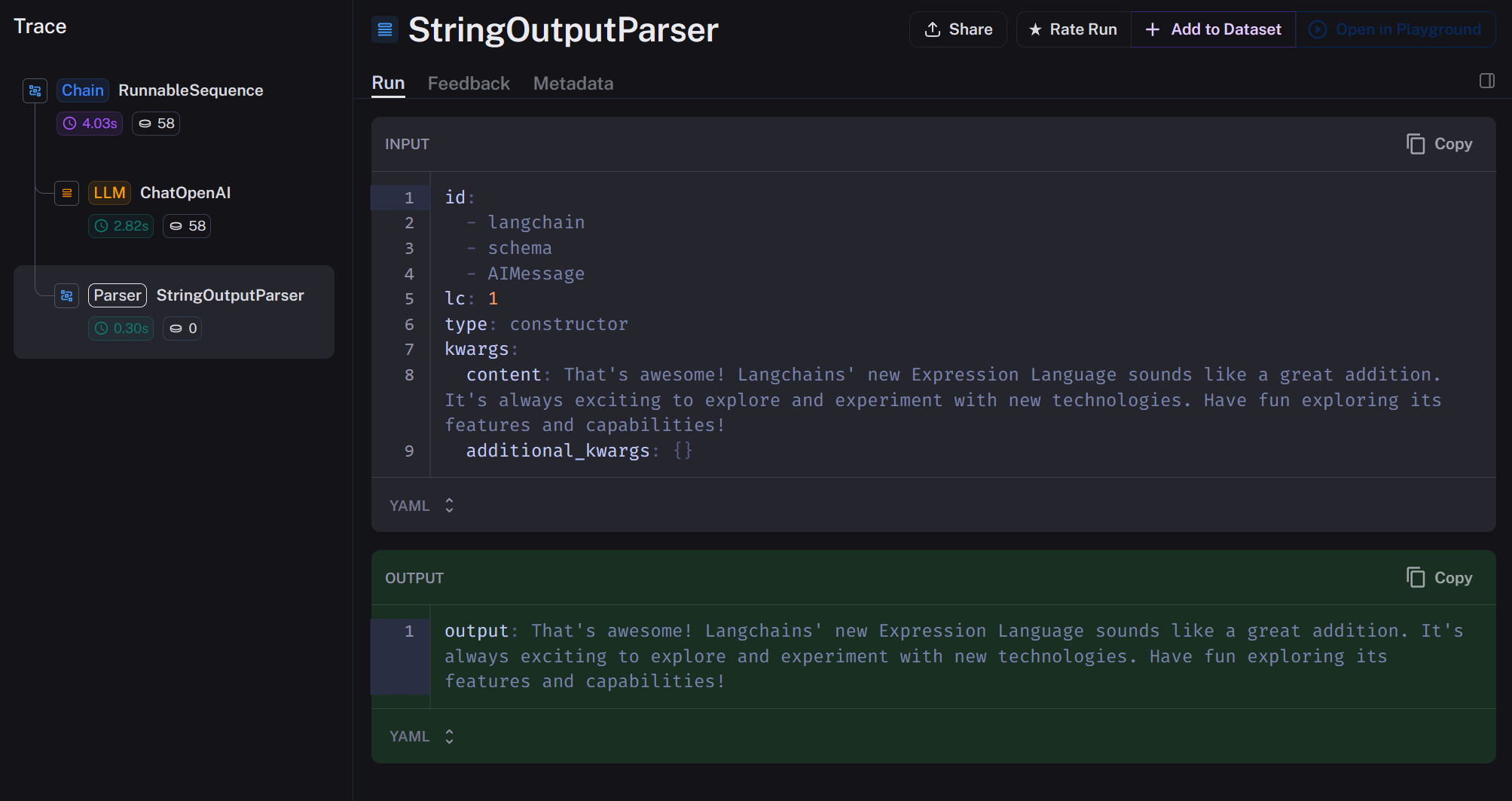
This will make our debugging process so much easier. We can see exactly what is going on and where something might go wrong.
Adding more Puzzle pieces
Let's go a bit further by expanding our chain, implementing a custom history and add some formatting instructions.
type ChainInput = {
userPrompt: Message;
chatHistory: Message[];
};
const result = await RunnableSequence.from([
{
chatHistory: (input: ChainInput) =>
input.chatHistory.map((msg) => `${msg.role}: ${msg.content}`)
.join(`\n`),
userPrompt: (input: ChainInput) => input.userPrompt.content,
formatInstructions: (input: ChainInput) =>
StructuredOutputParser.fromNamesAndDescriptions({
answer: "answer to the user's question",
summary: 'one sentence summary of the answer'
}).getFormatInstructions()
},
PromptTemplate.fromTemplate(
`chatHistory: {chatHistory}
userPrompt: {userPrompt}
formatInstructions: {formatInstructions}
your Answer:`
),
new ChatOpenAI({ openAIApiKey: PRIVATE_OPENAI_KEY }),
new StringOutputParser()
]).invoke({
userPrompt: requestData.messages.pop(),
chatHistory: requestData.messages
});And there we have it: custom chat history, formatting instructions and templating.
We added some really important features, and the code is still super concise and readable. How cool is that!
Our input for invoking the chain is the last message as UserPrompt and the rest as history.
Runnables accept single argument functions, so this allows us to convert the input to a type we can work with. This is so convenient, and I see myself using this a lot!
Then, in the first step of our runner consequence, we convert the user prompt to just the string by getting the content, and the chat history also to a string by joining the content of every message together.
The result of this gets passed into a template that replaces the placeholders with our variables.
The rest is the same like the last example. So in conclusion our flow goes as follows:
Invoke with Input -> Convert Input -> Fill Template -> Model call -> Parser
If we check LangSmith, we will see the chain call in detail.
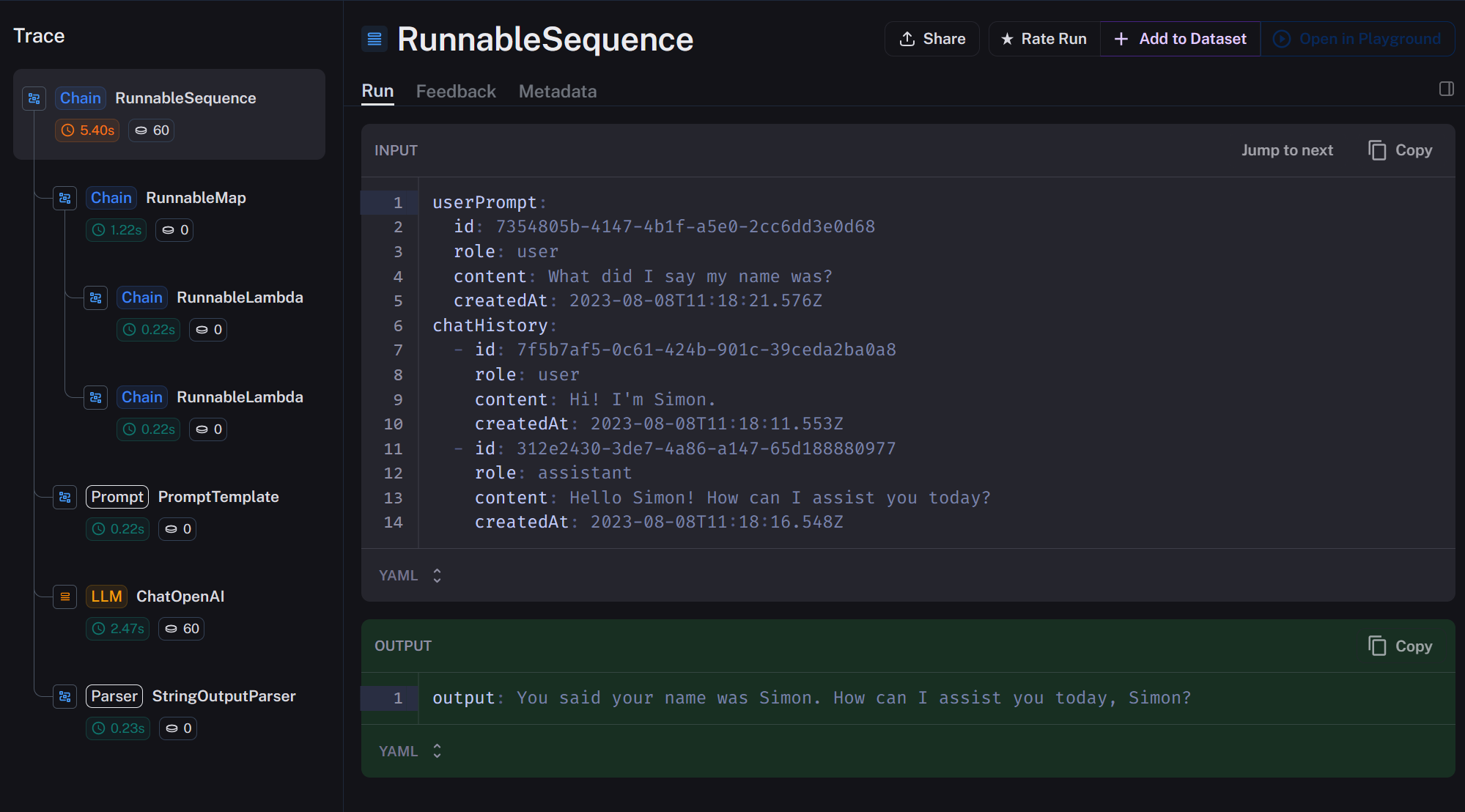
The biggest benefit of it all
What we gained by transitioning our chain to Expression Language is huge!
We can now swap out any part of our chain, with any other tool, parser, template etc. from LangChain and it should just work!
We built ourselves a puzzle where we can swap out any of the puzzle pieces very easily and build a new result with minimal effort. This is all made possible with the unified interface behind those runnable sequences.
Info: Customized agents are not yet supported to be plugged into a Sequence, but probably will be in the future.
Conclusion
In conclusion, the Langchain Expression Language improves developers coding experience by simplifying and enhancing code readability, promoting effortless debugging and maintenance.
It paves the way for personalized combinations and modifications, thanks to a unified interface that accommodates all Langchain building blocks.
With improved async support and the introduction of new methods like invoke, batch, and stream, handling various inputs and executing complex operations is now a breeze.
Ultimately, It will be my new defacto way to use Langchain and I can not wait to experiment more with it.
To learn more I encourage you to watch this video from the Langchain-Team: LangChain Expression Language or check out the official documentation.
Thank you for reading, I had a blast trying Expression Language and writing this! See you in the next one! 👋