
Dalle-3: Oil painting of a chatbot designed as an ethereal human head made of glowing energy threads. Hovering above is a constellation in the shape of 'QA Chatbot'
Introduction
Today, we're diving into the exciting world of QA (Question and Answer) Chat Applications. This is currently one of the most useful and common use-cases for LLM-centered applications.
I highly encourage you to check out my previous blog post on "the easiest chatbot", as it is the foundation for this blog post. It is designed to give you a good understanding of the basics of chatbots, concepts, and libraries used.
Today's post serves as a natural progression, enhancing our chatbot's capabilities by enabling it to use any data as a knowledge base.
Basically, we are giving AI a "brain". How cool is that! 🤯
Live deployment: Try the example here!
Github Repository: Check the code here!
Shortcomings of Chatbots
In our last exploration, we delved into creating a chatbot that efficiently leveraged OpenAI's knowledge to answer questions and stream those responses back to the user.
While impressive, we soon realized that relying solely on OpenAI's existing knowledge might fall short for specialized use cases.
That's where QA applications come in!
What is a QA Chatbot?
A QA (Question and Answer) Chatbot is a chatbot that is able to answer questions based on a given knowledge base.
For example, if you have a knowledge base of all the different types of apples, you could ask your chatbot "What is a Granny Smith?" and it would be able to answer that question.
While this might seem like a simple task, it actually has quite a lot of nuances to it, especially if you want to do it well.
For us to achieve this, we need to learn two new concepts:
- Ingestion: The process of integrating pertinent data into a vector database, a step also referred to as "ingestion."
- Retrieval Augmented Generation (RAG): This involves checking your vector database for details relevant to a user's query, extracting it, and seamlessly incorporating it into your system's response to enhance your LLM's contextual understanding.
In simpler terms, these functionalities are essential for teaching our LLM the ability to recall information from a knowledge base and use it to answer questions.
My goal for this blog post is to give you a really good example to work from. It should be simple to understand but powerful as a baseline.
Technologies
We will keep the technology/library stack exactly the same as in the previous example (SvelteKit, Langchain, Vercel AI SDK) and add one new one to our toolkit.
- Vercel Postgres: As a vector database for ingestion and retrieval of embeddings.
For a detailed explanation of these technologies, I encourage you again to check out the previous blog post.
Ingestion
Let's start with preparing our "brain's" knowledge. For that, we will go through a process called "ingestion", in which we will preprocess and then store the data we want to be able to retrieve later.
"In the context of data processing and computing, ingestion refers to the process of importing, transferring, loading, or acquiring data from various sources into a system or database for storage, analysis, or further processing."

Dalle-3: An illustration depicting the Embedding Generation process: Raw data is processed through a sophisticated model, resulting in the creation of a numerical vector.
Ingestion for LLMs is usually done by converting your data (be it pdf, csv, urls, transcripts, etc.) in a specific format called Documents.
For our use-case, we'll be leveraging a URL Loader to scan and capture content from the Langchain JavaScript documentation. This extraction results in said 'documents' which we can then further use for ingestion.
async function loadApiDocs() {
const url = 'https://js.langchain.com/docs/get_started/introduction';
const compiledConvert = compile({ wordwrap: 130 });
const loader = new RecursiveUrlLoader(url, {
extractor: compiledConvert,
maxDepth: 8,
preventOutside: true,
excludeDirs: ['https://js.langchain.com/docs/api/']
});
return await loader.load();
}We then use chunking to split these documents into smaller pieces because large documents might contain a lot of irrelevant information. By chunking and then vectorizing, there's a better chance that each vector represents a coherent piece of information, reducing the noise in the vector space.
async function splitDocs(docs: Document[]) {
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 4000,
chunkOverlap: 200
});
return await splitter.splitDocuments([...docs]);
}The final step in this phase involves transforming these chunks into 'embeddings' using OpenAI's embedding model, subsequently storing them in our Vector database.
For this example, we will use Vercel's Postgres (with PgVector under the hood) as the Vector database.
It's really simple to set up, especially if you are already using Vercel to host your project. Check the official documentation to set up the database.
The code we need on our ingestion endpoint is:
async function initVectorDb() {
const config = {
tableName: 'langchain_docs_embeddings'
};
return await VercelPostgres.initialize(
new OpenAIEmbeddings({
batchSize: 512 // Default value if omitted is 512. Max is 2048
}),
config
);
}Finally, after we have all the puzzle pieces in order, we can now put all these steps together and ingest our data!
const docs = await loadApiDocs();
const split_docs = await splitDocs(docs);
const vercelPostgresStore = await initVectorDb();
result = await vercelPostgresStore.addDocuments([...split_docs]);Toggle to see the complete code for the ingestion endpoint:
For the sake of simplicity, I choose to trigger the ingestion process with a simple click of a button. In a production application, you might want to do a more involved process.
async function ingest() {
const res = await fetch('/api/ingest', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
});
}If we check our database, we will discover that each document has been saved as a distinct numerical vector representation called an embedding.
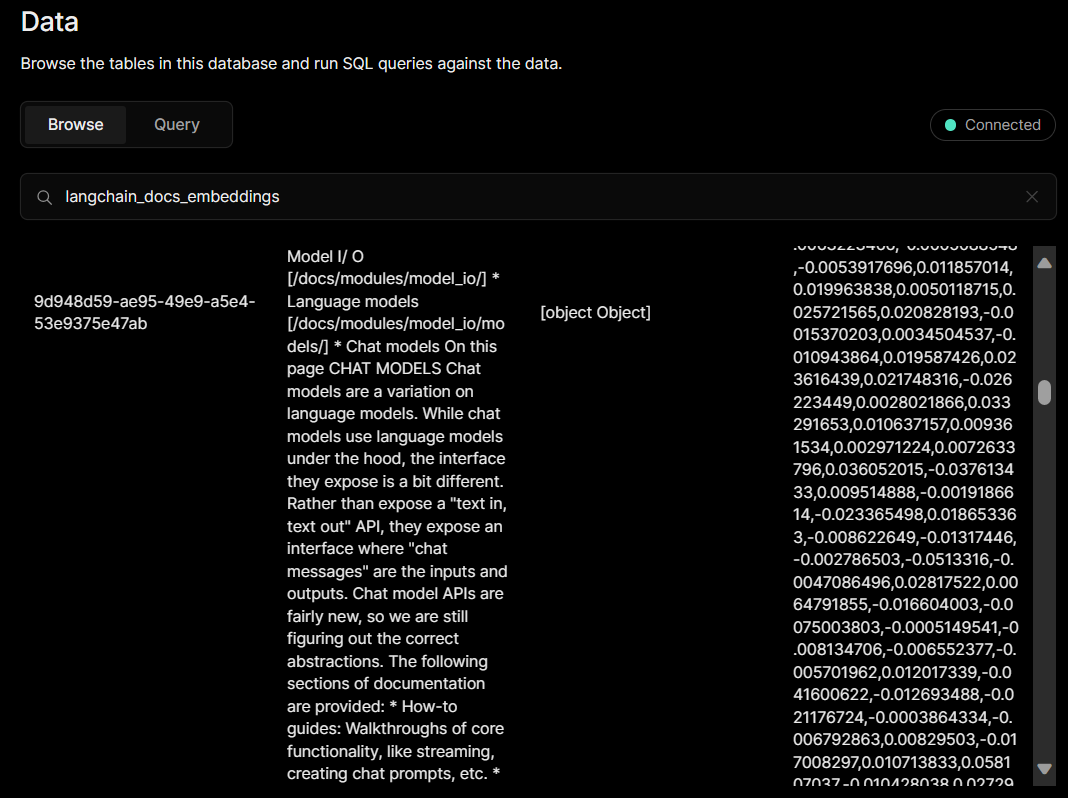
Later, when we want to retrieve information from our database, we will use similarity search based on user queries and pinpoint relevant information efficiently.
Just retrieving the data is not enough, though, which is how the concept of Retrieval Augmented Generation came to life.
Retrieval Augmented Generation (RAG)
Now that we've ingested our data, we can move on to the next step: Retrieval Augmented Generation (RAG).
" Retrieval Augmentation Generation (RAG) is an architecture that augments the capabilities of a Large Language Model (LLM) like ChatGPT by adding an information retrieval system that provides the data. Adding an information retrieval system gives you control over the data used by an LLM when it formulates a response. For an enterprise solution, RAG architecture means that you can constrain natural language processing to your enterprise content sourced from vectorized documents, images, audio, and video."

Dalle-3: A representation of the Querying/Retrieval step: A new piece of data is input into the system, which scans through the indexed embeddings to find matches.
As the name implies, this process involves retrieving relevant information from our vector database and incorporating it into our LLM's response to enhance its contextual understanding.
Imagine a user posing the question, "What is langchain expression language?" If our model (like ChatGPT) is unfamiliar with this term as it's absent from its training data, the answer would most likely be a "hallucination" or generally not helpful.
This is where our vector database comes to the rescue. Let's see how to setup our retriever:
const getRetriever = async () => {
const vectorstore = await VercelPostgres.initialize(new OpenAIEmbeddings({}), {
tableName: 'langchain_docs_embeddings'
});
return vectorstore.asRetriever({ k: 6 });
};The Vector store creates an embedding from the users question and checks if there is context that is close enough to that query. We are taking the 6 most similar documents and return them for further processing.
We want to use this in a chain that we can then use to retrieve the relevant information based on the users query. Our endgoal is to have "context" that we can inject into our llm.
One step we should take care of before though, is to format the users question into a standalone question.
Let's assume the user asked "What is expression language?" and then want's to dive deeper into one of the mentioned concepts by requesting "Explain sequences.".
If we do not process those questions the llm will have trouble understanding that the user is talking about "the concept of sequences in langchain expression language" and might explain a completely different topic.
We solve this by passing the users question and the chat history to a chain that will rephrase the history to a standalone question.
messages.length > 1
// condense into standalone question
? RunnableSequence.from([
{
question: (input: ChainInput) => input.question.content,
chat_history: (input: ChainInput) =>
input.chat_history
.map((message) => `${message.role}: ${message.content}`)
.join('\n')
},
PromptTemplate.fromTemplate(REPHRASE_TEMPLATE),
new ChatOpenAI({
modelName: 'gpt-3.5-turbo-16k',
temperature: 0
}),
new StringOutputParser()
])
//else -> return question as is
: input.question.content,You can check the rephrase template on Langchains Model Hub or by switching to mode.
Note: If there is no chat history, (messages.lenght === 1) there is no need to condense and we just return the question as is.
Great, now we have a question that we can use to retrieve relevant information from our vector database and use as context!
context: RunnableSequence.from([
// condense chain -> then pass question to retriever
getRetriever,
(docs: Document[]) =>
docs.map((doc, i) => `<doc id='${i}'>${doc.pageContent}</doc>`).join('\n')
]),The rest of the steps in our chain are really similar to the "easiest chatbot" example.
First we pass the users question, chat history and context into our prompt template.
For the response template we are once again using a prompt from the fantastic Langchains Model Hub. This prompt does an amazing job in instructing the llm to summarize effectively.
We send the now formated system and human messages to the llm and get a response back.
Finally we use the BytesOutputParser to chunk the response into smaller pieces and stream it.
ChatPromptTemplate.fromMessages([
['system', RESPONSE_TEMPLATE],
['human', `Chat History:{chat_history} {question}`]
]),
new ChatOpenAI({
modelName: 'gpt-3.5-turbo-16k',
temperature: 0
}),
new BytesOutputParser()Now all that is left is initializing our sequence and returning the stream to the frontend.
const stream = await chain.stream({
question: messages.pop(),
chat_history: messages
});
return new StreamingTextResponse(stream);Toggle to see the complete code for the rag endpoint:
If we now send a message in our frontend...

...We will see we now have a fully functional QA Chatbot that can answer questions based on a knowledge base! Awesome!🎉
Conclusion
We've successfully created a chatbot that can answer questions based on a knowledge base. This is a huge step forward in terms of the capabilities of our chatbot, and it's all thanks to Retrieval Augmented Generation (RAG).
We've also learned how to use Vercel Postgres as a vector database, for ingestion as well as retrieval!
As always, I hope you enjoyed this blog post and learned something new. If you have any questions or feedback, feel free to reach out to me on Twitter or send me a message through the contact form.
Thank you for reading and see you again next time!👋
Additional Resources
This example is heavily inspired by Langchains "Chat Langchain"!
I highly recommend their blog post on this topic and looking at their implementation on the official repository.
While our examples are similar in result I decided to use a few different approaches, most namely the choice of JS Framework, Vector DB, Ingestion in JS and the use of the Vercel AI SDK.
I believe there is value learning from both implementations!